

Baidu Qianfan-VL is open source, and the purely domestically developed Kunlun chip achieves world-class performance

百度開源了全新的視覺理解模型 Qianfan-VL,包含 3B、8B 和 70B 三個版本,均在自研的崑崙芯 P800 上訓練。Qianfan-VL 是一種多模態大模型,具備 OCR 和教育場景深度優化能力,能識別各種文字和複雜公式。在科學問答測試中,70B 版本獲得 98.76 分,在中文多模態基準測試中得分 80.98,顯示出其在中文圖文理解上的優勢。
百度把他們全新的視覺理解模型 Qianfan-VL 直接開源了。

Qianfan-VL 系列一共有三個版本,3B、8B 和 70B,參數量從小到大,分別對應不同的應用場景。
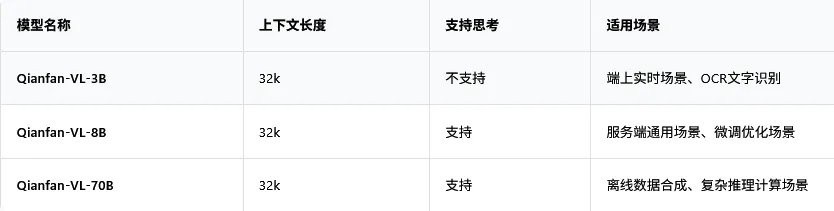
模型從頭到尾,都是在百度自己家的芯片崑崙芯 P800 上訓練出來的。
模型的性能和應用
Qianfan-VL 是一個多模態大模型,就是那種既能看懂圖片又能理解文字的 AI。一張複雜的圖表,它能分析出裏面的數據和趨勢。
它最核心的兩個本領是 OCR(光學字符識別)和教育場景的深度優化。
你拍一張身份證,系統自動把你的姓名、證件號填好,這就是 OCR。Qianfan-VL 把這項能力做到了全場景覆蓋,不管是印刷體、手寫字,還是藏在街邊招牌、商品包裝袋上的藝術字,甚至是數學卷子上的複雜公式,它都能識別。發票、單據裏的信息也能自動抽出來,變成結構化的數據。
而在教育場景,特別是 K12(從幼兒園到高三)階段,它的目標就是成為一個超級學霸。拍照解題、幾何推理、函數分析,這些都是它的強項。
Qianfan-VL 和國際上幾個主流的多模態模型跑分對比。
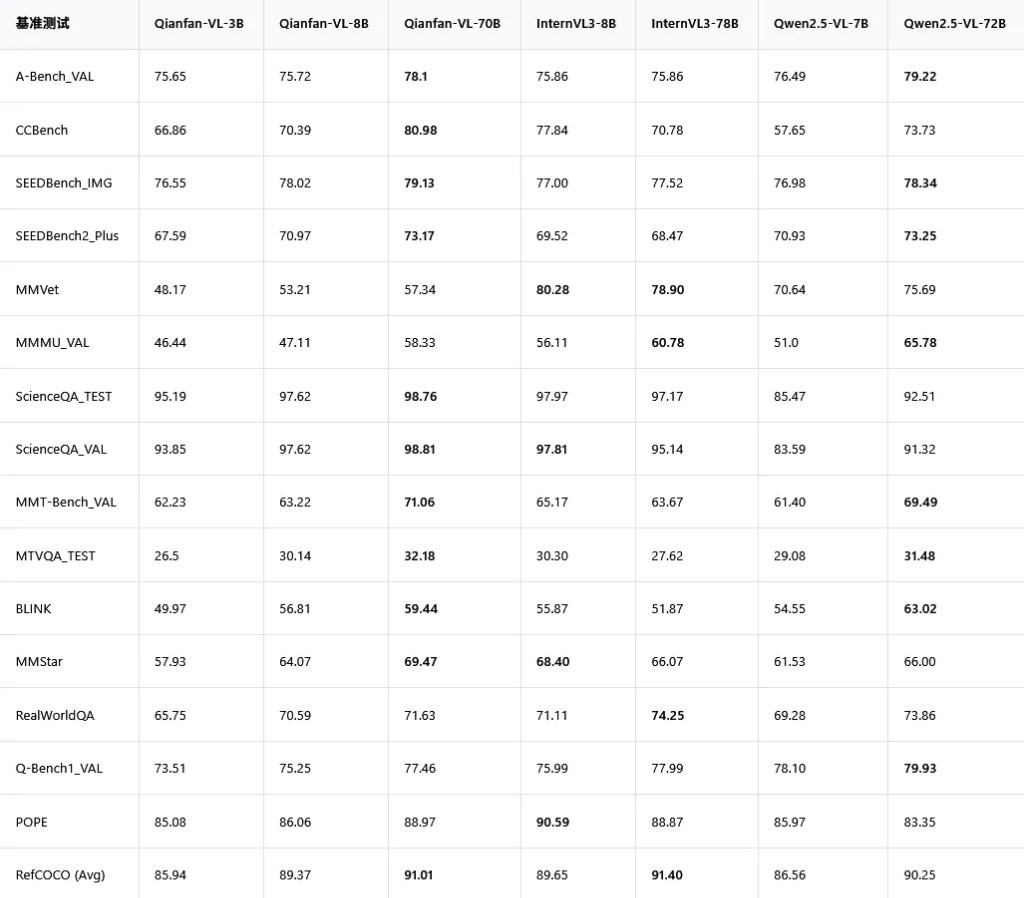
在科學問答測試 ScienceQA 裏,70B 版本的 Qianfan-VL 拿到了接近滿分的 98.76,把一眾對手甩在身後。
尤其是在中文多模態基準測試 CCBench 中,Qianfan-VL-70B 拿到了 80.98 分,而同級別的對手只有 70 分出頭。這説明它在理解中文語境下的圖文內容時,優勢非常明顯。
在數學解題相關的幾項測試,比如 Mathvista-mini,Math Vision 和 Math Verse 裏,Qianfan-VL-70B 幾乎是碾壓式的領先。
純血國產芯片訓練
支撐 Qianfan-VL 模型訓練的,是百度自研的崑崙芯 P800 芯片。
2025 年 4 月,百度點亮了國內首個全自研的 3 萬卡崑崙芯 P800 集羣。Qianfan-VL 的所有訓練任務,都是在一個超過 5000 張崑崙芯 P800 卡的集羣上完成的。
崑崙芯 P800 是個什麼水平?
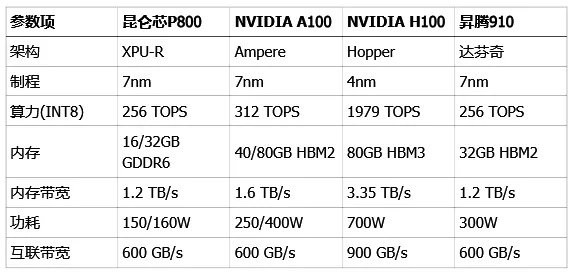
從紙面參數看,崑崙芯 P800 有一個非常突出的優點,就是功耗控制得極好,150W 到 160W 的功耗,遠低於競爭對手。這意味着在組建大規模集羣時,能耗和散熱成本會更有優勢。
崑崙芯 P800 真正的殺手鐧在於它的架構設計。
P800 的 XPU-R 架構,從硬件上就把計算單元和通信單元分開了。這就好比把單行道改成了雙向八車道,旁邊還修了條專門給行人走的人行道。計算和通信各走各的路,互不干擾,可以同時進行。
百度把這個技術叫做 “通算融合”。通過精巧的調度,可以讓數據傳輸的等待時間,完全被計算過程所掩蓋。比如,在計算第一塊數據的時候,第二塊數據已經在傳輸的路上了,等第一塊算完,第二塊正好無縫銜接。這樣一來,芯片的利用率被大大提高了。
基於這種能力,百度還推出了 “崑崙芯超節點” 方案,能把 64 張崑崙芯 P800 塞進一個機櫃裏。卡與卡之間的數據交換從速度較慢的 “機間通信” 變成了速度飛快的 “機內通信”,帶寬直接提升 8 倍,單機訓練性能提升 10 倍。
模型是這麼煉成的
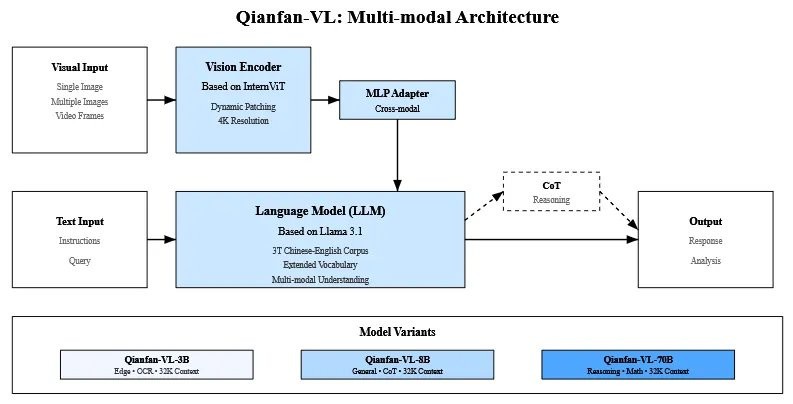
它的底層架構融合了業界的優秀成果。語言模型部分,小參數的 3B 版本基於 Qwen2.5,而主力 8B 和 70B 版本則基於 Llama 3.1。視覺編碼器用了 InternViT,最高能處理 4K 分辨率的超高清圖像。
精髓在於它的訓練方法,百度設計了一套創新的 “四階段訓練管線”,像一個精密的四步升級程序。
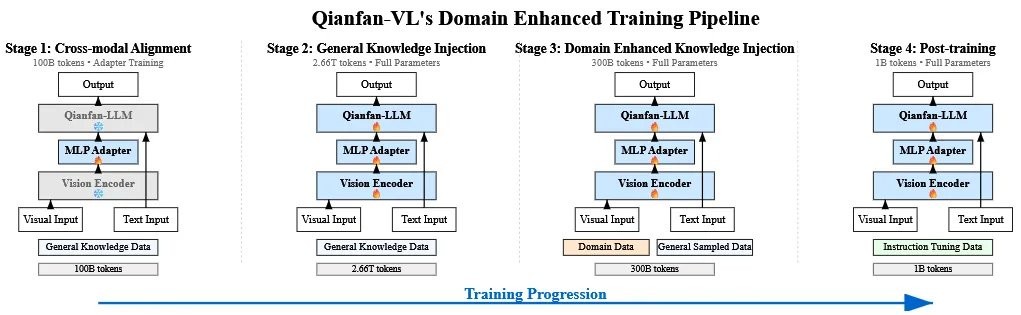
“跨模態對齊”。這個階段的目標很簡單,就是先讓模型的語言部分和視覺部分認識一下,建立最基礎的連接。訓練的時候,只更新它倆之間的連接件(一個叫 MLP Adapter 的東西),語言和視覺模塊本身都先凍結,避免互相影響。
“通用知識注入”。這個階段開始給模型瘋狂 “喂” 數據,總共投餵了 2.66T tokens 的通用知識數據。同時,模型的全部參數都放開進行訓練。這個階段的目標是為模型打下堅實的通識基礎,讓它成為一個見多識廣的 “通才”。
“領域增強知識注入”。在成為 “通才” 之後,就要開始培養它的 “專長” 了。百度精選了大量高質量的 OCR、文檔理解、數學解題等領域的數據,對模型進行專項強化訓練。為了防止模型在學習專業知識時忘記了通用知識(這個現象在 AI 訓練中被稱為 “災難性遺忘”),訓練時還會摻入一部分通用數據。
“後訓練”。經過前三個階段,模型已經能力很強了,但可能還不太 “聽話”。這個階段就是通過大量的指令微調數據,教模型如何更好地理解和遵循人類的指令,讓它變得更像一個得力的助手。
第三階段使用的專業數據,是百度通過一套高精度數據合成管線自己 “造” 出來的。
目前,Qianfan-VL 的全系列模型已經在 GitHub 和 Hugging Face 等平台全面開源,企業和開發者可以自由下載使用。
百度智能雲的千帆平台也提供了在線體驗和部署服務。
GitHub:
https://github.com/baidubce/Qianfan-VL
Hugging Face:
https://huggingface.co/baidu/Qianfan-VL-70B
https://huggingface.co/baidu/Qianfan-VL-8B
https://huggingface.co/baidu/Qianfan-VL-3B
ModelScope:
https://modelscope.cn/organization/baidu-qianfan
風險提示及免責條款
市場有風險,投資需謹慎。本文不構成個人投資建議,也未考慮到個別用户特殊的投資目標、財務狀況或需要。用户應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。
