

Xiaomi's latest large model achievement! Luo Fuli has appeared

The Xiaomi AI team, in collaboration with Peking University, has released a paper on MoE and reinforcement learning, with Luo Fuli as the corresponding author. The paper proposes an approach to improve the efficiency and stability of large model reinforcement learning within the MoE architecture, addressing instability issues during the training process. The research indicates that reinforcement learning is crucial for driving breakthroughs in large model capabilities, especially when pre-training encounters bottlenecks
Xiaomi's latest large model research results have been publicly revealed.
Recently, the Xiaomi AI team collaborated with Peking University to jointly publish a paper focusing on MoE and reinforcement learning.

Among them, Luo Fuli, who transferred to Xiaomi before the explosive success of DeepSeek R1, is also prominently listed as a co-author.
Luo Fuli graduated with a master's degree from Peking University, and this time it can be said that AI has connected Xiaomi and Peking University.
Interestingly, when DeepSeek was featured in Nature this September, Luo Fuli also appeared on the author list, but as an "independent researcher from Beijing."

At that time, there were rumors that "Lei Jun hired the AI genius girl with a salary of tens of millions," suggesting that the individual might have left the company.
However, after the disclosure of this latest AI paper from Xiaomi, everything seems to have an answer...
Xiaomi's Latest AI Achievement: Finding the Balance Between Stability and Efficiency in RL
This paper is straightforward, proposing a method to enhance large model reinforcement learning within the MoE framework.
It is widely agreed that reinforcement learning has become a key tool for pushing the boundaries of LLM capabilities after encountering bottlenecks in pre-training.
However, in the MoE framework, the situation is not so simple. Due to the need to allocate different experts based on the problem, the routing mechanism can make the training process unstable, and in severe cases, it can even cause the model to "collapse."
To address this issue, the research team proposed a completely new approach that allows MoE to advance large-scale reinforcement learning smoothly and efficiently.
Catastrophic Collapse of Reinforcement Learning
Since the end of the pre-training era, post-training has become the next battlefield that giants are targeting with Scaling Law.
With large-scale reinforcement learning, large models have begun to learn longer chain reasoning and can handle complex agent tasks that require tool invocation.
However, in the process of scaling reinforcement learning, there is inevitably a barrier: the trade-off between efficiency and stability.
To achieve high efficiency, training must be more "aggressive"—higher learning rates, greater parallelism, and more frequent sample updates. But this can lead to more stability issues.
On the other hand, pursuing stability alone is not feasible, as efficiency will be hindered, causing model training to slow down to a crawl.
To solve this problem, one must first delve into the fundamentals of reinforcement learning.
Reinforcement learning for LLMs typically consists of two steps:
The first step is inference, where the model generates content, interacts with the environment, and receives feedback scores;
The second step is training, fine-tuning oneself based on these scores, and finding ways to achieve higher scores next time.
However, these two steps are usually not run in the same system.
For example, the mainstream solution now is that SGLang is responsible for content generation, pursuing speed; while Megatron is responsible for training updates, pursuing accuracy.
Although both sides use the same model parameters, there are subtle differences in the underlying implementation, such as randomness, precision, parallelism, and caching strategies. These seemingly trivial details can cause deviations in the results.
This has led to an awkward phenomenon:
The same prompt can yield different results under the two modes.
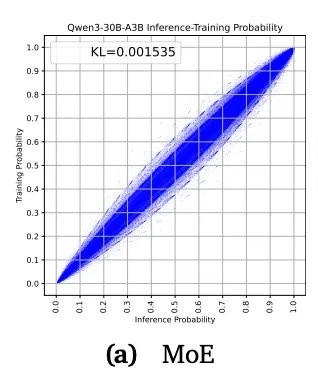
As this "probability drift" accumulates, the model will learn more and more off-track, ultimately leading to a complete mismatch between the training objectives and actual performance.
This is what is commonly referred to in the industry as the catastrophic collapse of reinforcement learning.
Routing Replay Mechanism
The research team pointed out that the main culprit for MoE easily collapsing in reinforcement learning is the routing distribution.
In MoE models, routers do not use all parameters but instead select a few "experts" who are more proficient in the relevant field based on the characteristics of each input token, thus saving a lot of resources.
However, the side effect is also very obvious; this dynamic mode can lead to a significant disparity between the best strategies derived during the training phase and the inference phase, making it much more "volatile" than traditional dense models.
In response, this paper provides a novel solution.
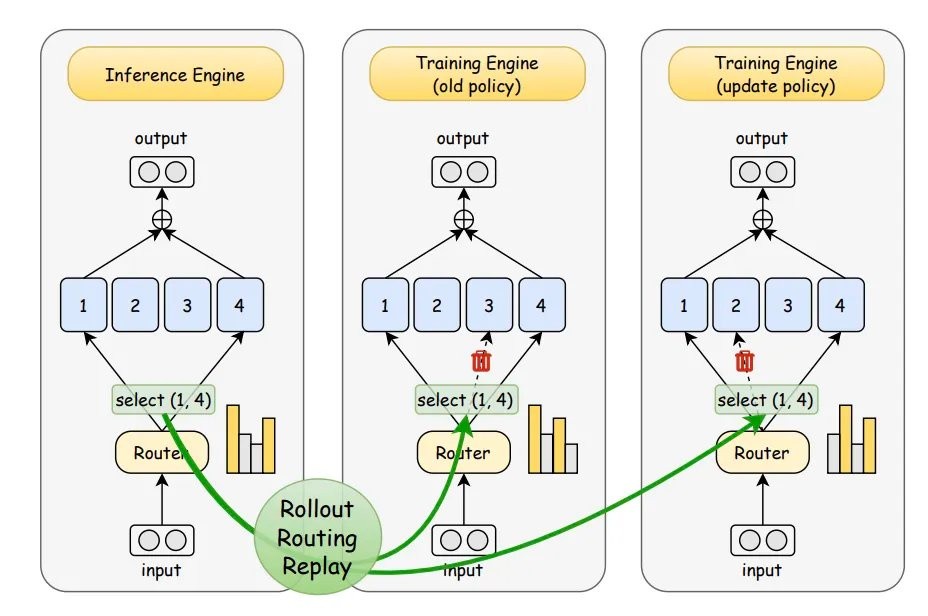
Since the problem lies in routing randomness, why not simply lock the routing?
Their approach is to record the routing distribution during inference and then "replay" these distributions unchanged during training.
This way, training and inference follow the same path, no longer working independently.
Based on this "replay" characteristic, the research named this method—Rollout Routing Replay (R3).
Having solved the stability issue, let's see how to also secure efficiency.
In reinforcement learning, the model continuously repeats the cycle of "generate → receive reward → update → generate again," which may require tens of thousands or even millions of inference runs for a complete process.
If each generation has to recalculate the context from scratch, the computational and time costs will grow geometrically.
To address this situation, mainstream inference engines generally adopt the KVCache prefix caching strategy: saving the previously calculated context so that the next time it can "continue calculating." However, in addition to the inconsistency in context, the MoE architecture also involves the issue of inconsistent routing choices—according to traditional solutions, even with repeated contexts, the model still has to re-select experts and activate them for each computation.
Therefore, the research team added another layer on top of KVCache—routing mask.
Their idea is that since the routing results for the same context in MoE should be the same, they might as well cache the routing mask from the inference phase along with the prefix KVCache.
This way, when the same context appears again, the model can directly use the previous mask without recalculating.
As a result, R3 can seamlessly integrate with the existing prefix caching system, maintaining excellent computational efficiency even in large-scale reinforcement learning and complex agent tasks.
Experimental Results
To evaluate the actual effectiveness of R3, the research team conducted a series of experiments based on the Qwen3-30B-A3B model.
Overall Performance:
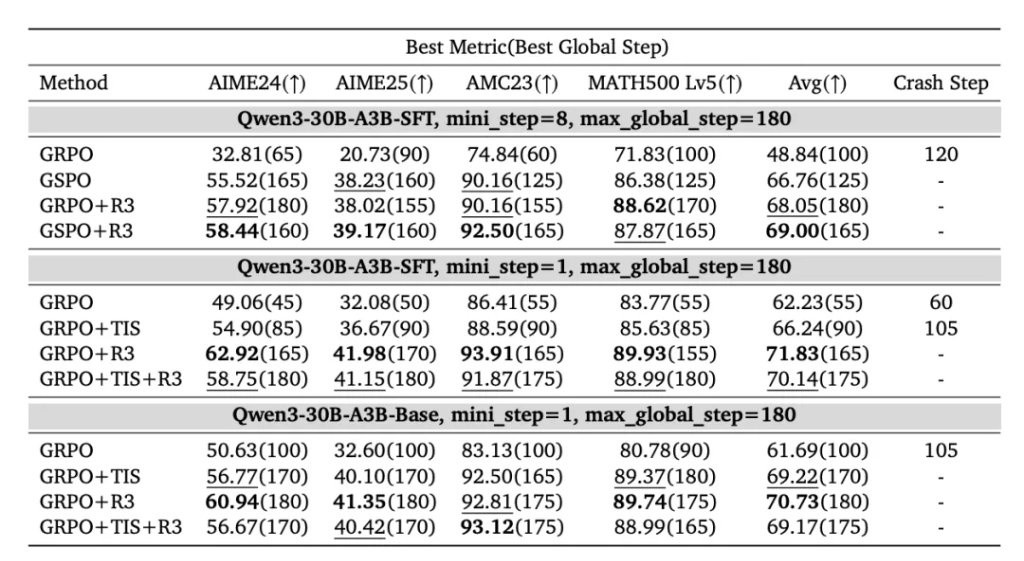
The results showed that R3 performed better overall in all scenarios.
In the multi mini-step setting, the performance of GRPO+R3 was 1.29 points higher than that of GSPO.
If R3 is combined with GSPO, performance can be further improved by 0.95 points.
Training Stability:
The number of crashes has also decreased significantly.
It is evident that as training time extends, even at the 150th step, R3 still maintains a relatively smooth curve.
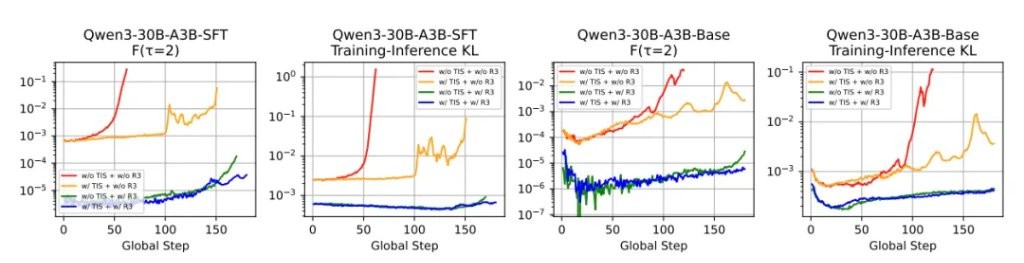
In contrast, if trained with GRPO, it has already deviated significantly by the 60th step.
Optimization and Generation Behavior:
Moreover, R3 not only stabilizes the model but also makes it smarter.
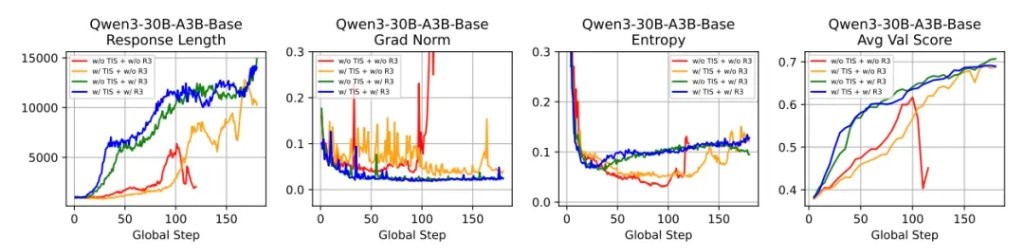
The experimental results indicate that R3 can find the correct direction faster, optimize the process more smoothly, and start exploring better strategies earlier.
In summary, the research team proposed a method called R3 in this paper, which, by reusing the routing distribution from the inference phase during training, enables more stable and efficient reinforcement learning for MoE models.
Paper Authors
Having discussed the paper, let's take a look at the research team formed by Xiaomi and Peking University The first author of the paper is Wenhan Ma.
There is not much information available, only that Wenhan is a researcher in the Xiaomi LLM-Core team and is also an intern.
Previously, he participated in the development of Xiaomi's MiMo model and the multimodal MiMo-VL.

In comparison, the two corresponding authors of this paper may be more familiar to everyone.
One is Luo Fuli.

Luo Fuli graduated with a bachelor's degree in Computer Science from Beijing Normal University and pursued a master's degree in Computational Linguistics at Peking University. During this time, she published papers at several top NLP conferences.
After graduating with her master's degree, Luo Fuli joined Alibaba DAMO Academy as a researcher in the Machine Intelligence Laboratory, responsible for developing the multilingual pre-trained model VECO and promoting the open-source work of the AliceMind project.
In 2022, Luo Fuli joined DeepSeek's parent company, Huanfang Quantitative, to engage in deep learning-related work, and later became a deep learning researcher at DeepSeek, participating in the development of models such as DeepSeek-V2.
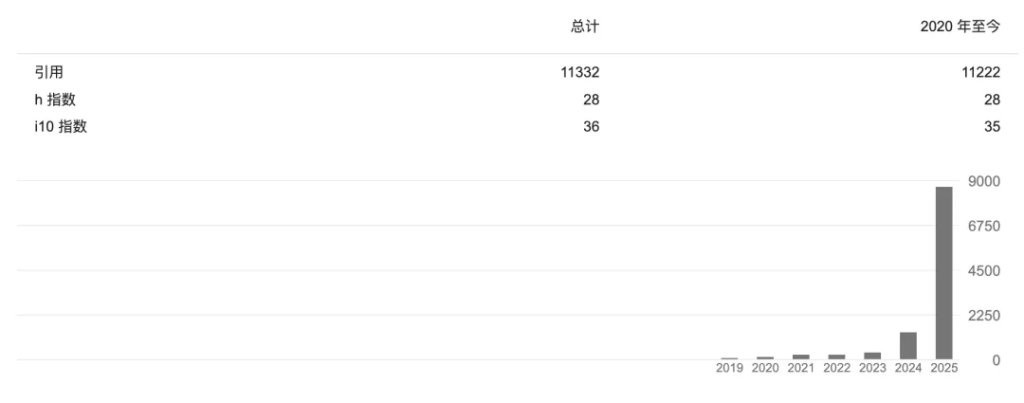
As of now, Luo Fuli's academic papers have been cited over 11,000 times in total, with approximately 8,000 citations added just this year.
The other corresponding author is Luo Fuli's master's advisor at Peking University—Sui Zhifang.

Professor Sui is a professor and doctoral supervisor at the School of Information Science and Technology at Peking University, engaged in research on computational linguistics, text mining, and knowledge engineering, and has published a large number of high-level papers in the fields of NLP and AI.
However, there is a new question: in the unit annotation of the paper's results, Luo Fuli's affiliation is not clearly stated; she is neither affiliated with Peking University nor categorized under Xiaomi.
 Oh... still an independent researcher?
Oh... still an independent researcher?
Risk Warning and Disclaimer
The market has risks, and investment should be cautious. This article does not constitute personal investment advice and does not take into account the specific investment goals, financial situation, or needs of individual users. Users should consider whether any opinions, views, or conclusions in this article align with their specific circumstances. Investing based on this is at one's own risk
